Искусство по-прежнему в большом долгу
Играюсь тут с ИИ - с ChatGPT и с Bing AI.
Я сейчас нахожусь в городе Реус (приехал на одну ночь, сегодня уже домой), ну и решил спросить у тополя и ясеня, что именно здесь, в Реусе, посмотреть, благо мы все уже посмотрели, так что сможем оценить ответы.
Вопрос в обоих случаях звучал так: "Что интересного можно посмотреть в городе Реус в Каталонии"?
Bing не мудрствовал. Перевел вопрос на английский (он по-русски пока не умеет), и сделал предельно краткую, но относительно толковую выдержку из 5 источников, которую оптимальной никак не назвать (кафедральный собор он даже не упомянул), но как-то ориентироваться по ответу можно.
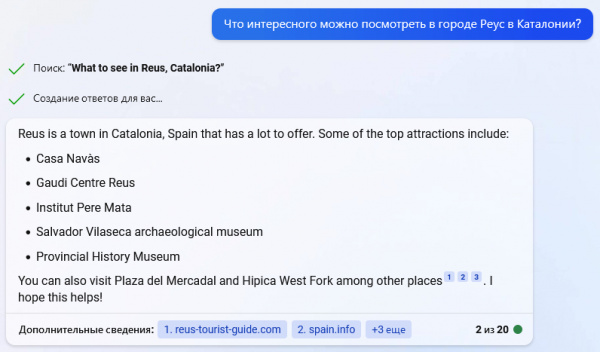
ChatGPT выдал намного более "интеллектуальный" ответ, в котором конкретно облажался аж в 3 пунктах из 5.
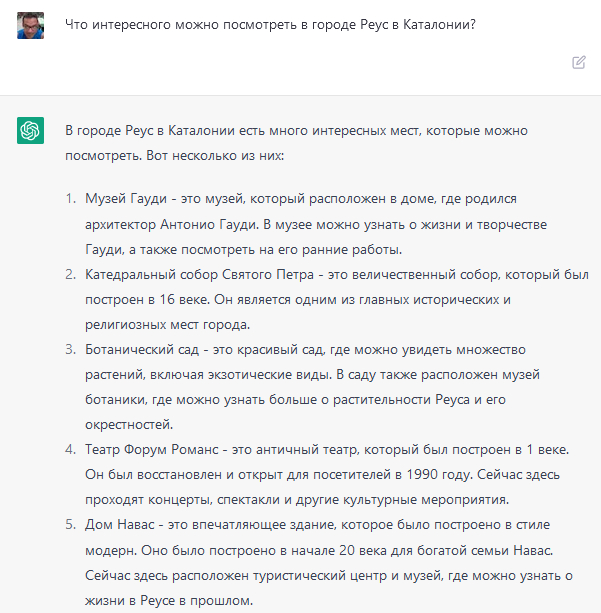
1. Антони Гауди действительно родился в Реусе, в этом городе действительно расположен Музей Гауди (он же является туристическим центром), однако дом, где Гауди родился, никак не является музеем: это обычный частный дом, на котором просто висит табличка, сообщающая о том, что великий архитектор здесь родился. Вот я этот дом вчера сфотографировал.

Музей расположен недалеко, но в совершенно другом здании на Рыночной площади, куда идти от дома, где Гауди родился, минут 7 - вот оно на снимке Рыночной площади в дальнем углу справа, на нем выведена цветастая картинка на огромном мониторе. А здание по центру левее - это знаменитый Дом Навас, о котором говорится в пункте 5 ChatGPT. Кстати, здание Дома Навас в Сети почему-то часто называют "Музеем Гауди", что прям совсем неправда.

2. Кафедральный собор Святого Петра (Iglesia Prioral de San Pedro) - да, тут все четко.

3. Ботанический сад
Никакого Ботанического сада в Реусе и в окрестностях нет. В тех краях есть ботанический Parc Samà, куда мы сейчас как раз собираемся, однако это 45 минут езды на электричке или 20 минут езды на машине, и уж если его хочется назвать чьим-то Ботаническим садом, хотя он совершенно отдельный, но проще сказать, что это Ботанический сад Камбрильса - тот к саду ближе, чем Реус.
4. Театр Форум Романс
Это вообще редкостная бредятина. Судя по всему, имеются в виду раскопки римского форума, но ближайший от Реуса римский форум находится в Таррагоне, городе, знаменитом своими находками римских времен (я писал о Таррагоне и достопримечательностях этого города), и это Colonial Forum of Tàrraco Таррагоны, никак не Реуса.

Представляю себе туристов, которые носятся по Реусу и спрашивают: "Где здесь раскопки Римского форума, подскажите, плиз", - на них посмотрят как на идиотов.
5. Дом Навас
Действительно - одна из главных достопримечательностей города (мы там вчера побывали на экскурсии), однако никакой туристический центр в нем не расположен (он расположен в Музее Гауди, который находится по соседству), и там также совершенно точно нет никакого музея истории Реуса, который расположен в совершенно другом месте, и мы там тоже вчера побывали.
В общем, у ChatGPT совсем незачет. Из пяти пунктов ответа первый - неточный, второй - годится, третий и четвертый - вообще бред, пятый - две серьезные ошибки.
Искусство ИИ, короче говоря, по-прежнему - в большом долгу.
Я задал вопрос что посмотреть в Одессе.
Один из пунктов был Одесский Литературный музей, расположенный во дворце Воронцова(неправильно, на самом деле дворец Гагарина) по адресу Ланжероновская 2(правильно)
Когда я спросил где находится дворец Воронцова, он ответил - Приморский Бульвар 1 (правильно)
То есть информация у бота есть, а он все равно привирает.
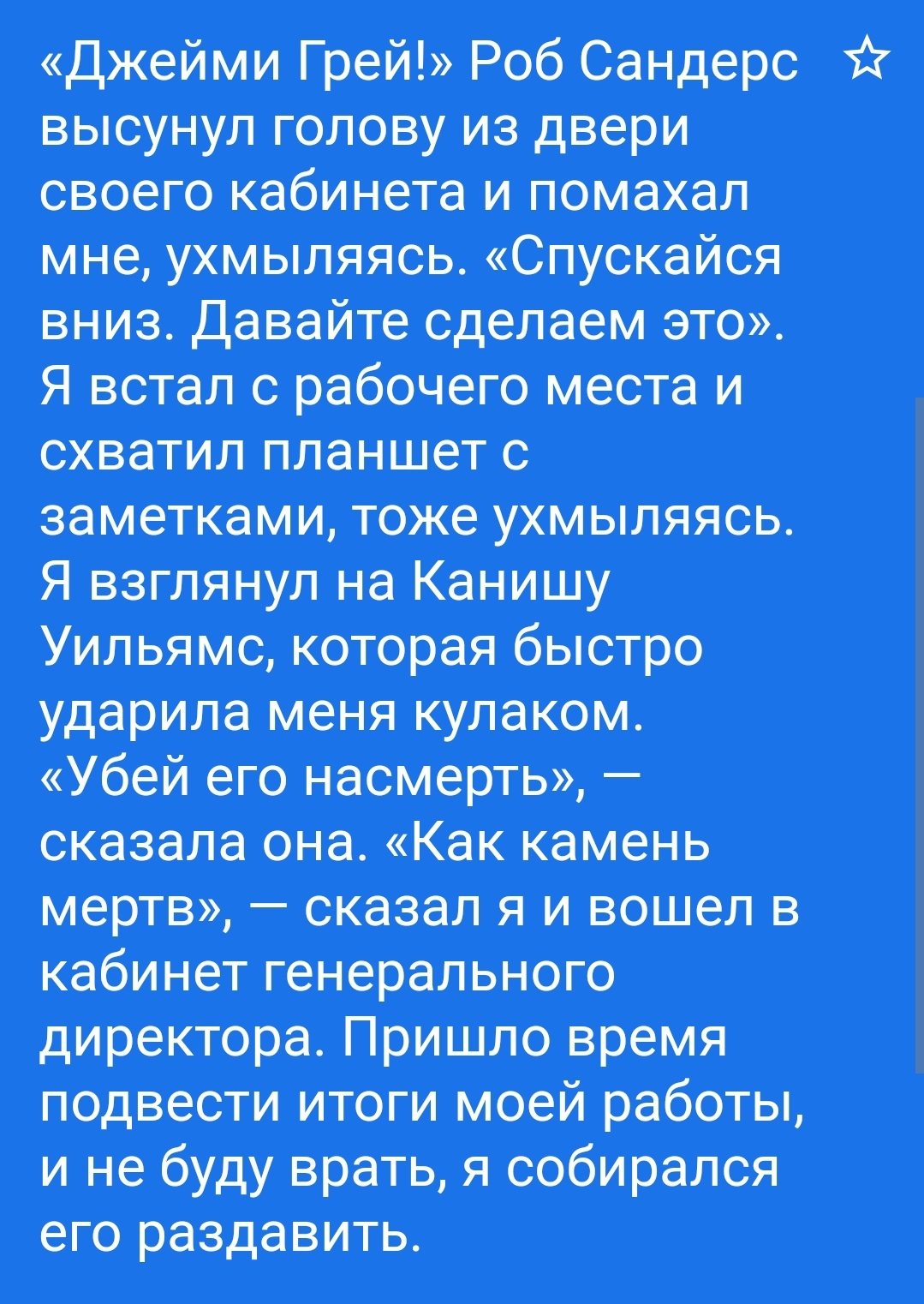
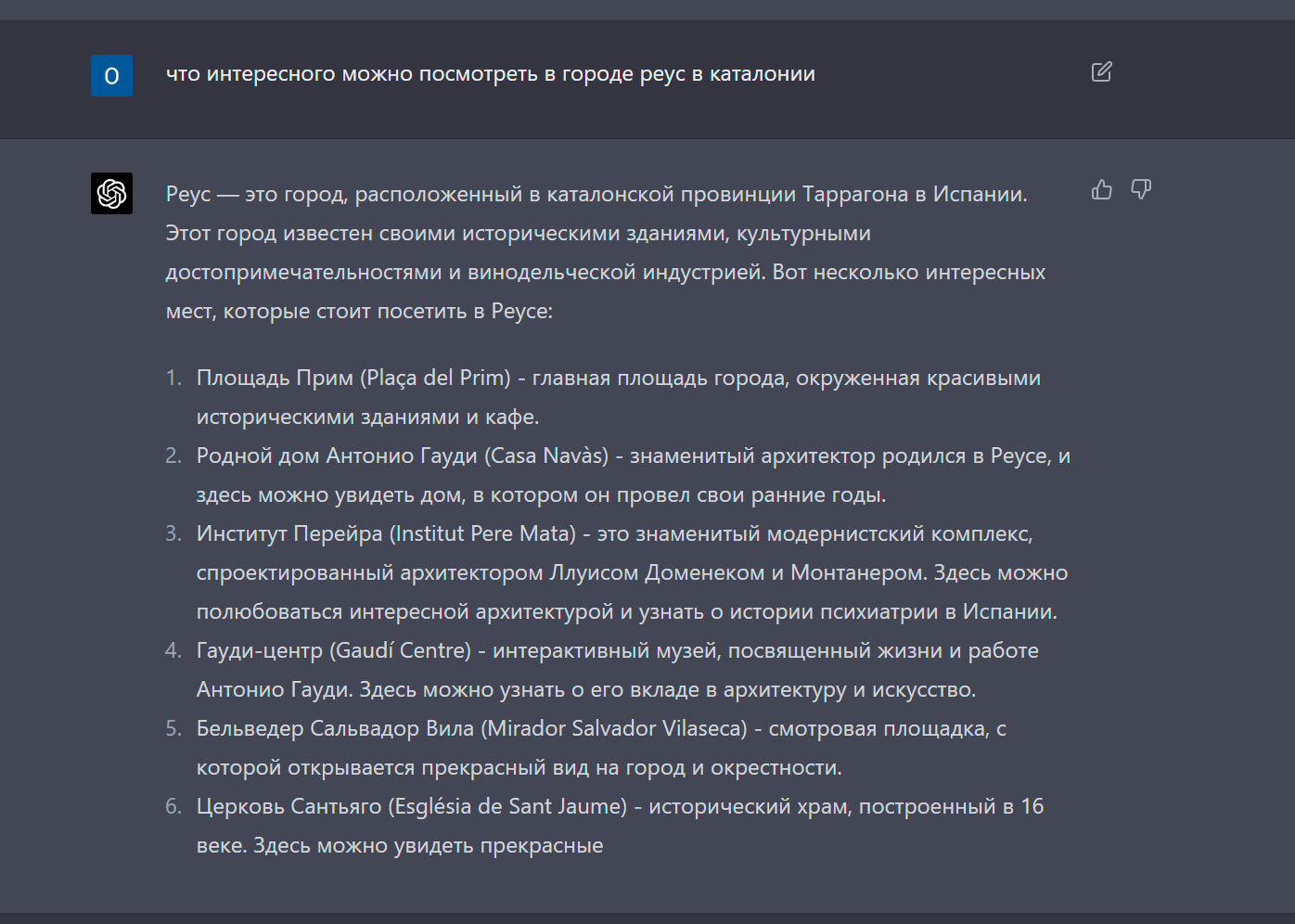
Реус - красивый город в Каталонии, Испания, с богатой историей и культурным наследием. Вот несколько мест, которые стоит посетить в Реусе:
Центр Гауди - музей, посвященный жизни и творчеству знаменитого каталонского архитектора Антонио Гауди.
Маршрут модернизма - экскурсия по зданиям в стиле модернизма, включая Casa Navas и Casa Gasull.
Музей археологии Реуса - музей, демонстрирующий историю города и его окрестностей, с артефактами из римского и средневекового периодов.
Музей Фортуни - музей, посвященный работам дизайнера Мариано Фортуни.
Prioral de Sant Pere - готическая церковь с красивым розовым окном и барочным алтарем.
Площадь дель Меркадаль - главная площадь города, окруженная историческими зданиями и кафе на открытом воздухе.
Музей-памятник Вердагера - музей, посвященный жизни и работам каталонского поэта Жакинта Вердагера.
Музей Сальвадора Виласеки - музей, демонстрирующий коллекцию искусства местного художника Сальвадора Виласеки.
Кал Массо - традиционный каталонский дом, преобразованный в культурный центр.
Дворец Бофарулль - дворец в стиле Ренессанса, который в настоящее время является мэрией.
Это всего лишь несколько мест, которые стоит посетить в Реусе. Благодаря красивой архитектуре, богатой истории и вкусной кухне, в этом прекрасном городе много чего можно увидеть и сделать.


Разговор закончился, не начавшись.
- Алиса!
- Да, принцесса?
- 😲 Какая я тебе принцесса?
- А я - королева!
- 🤦♂️Выключись.
А вы chatGPT, chatGPT...
Что ни скажи про любую ИИ-приблуду плохого (даже сугубо с технической точки зрения))) – один хрен глупые "фанаты" (ЧСХ, сами ни хрена не понимающие в технологиях) заминусуют вусмерть, как те индюки.
Учту. Впредь буду более аккуратен в выборе слов для такой публики (хоть и не обещаю)))....
Вокруг полно глупо-восторженныых поклонников этой хреновины (славтехосспидя, хоть автор не поддался этой массовой шизе))).
Слепые поклонники, которые видят лишь "вау-результат" – но понятия не имеют о том, как оно всё работает в реальности. А в реальности – тупо гугло/бинг поиск, потом минимальная обработка результата. ВСЁ! Но пипл массово хавает, зачем-то...
Это поиск в виде функционала ещё не завезли, это да.
Или, всё же, там конкретно собранная база знаний с веб-ресурсов? Ну, если хоть на минуту перестать слепо спорить и хоть чуточку подумать-то, откуда там взяться самим данным... 😉
P.S. При этом языковые модели, разумеется, тоже обучались параллельно. Одно другому совершенно никак не мешает и одно другого совершенно никак не исключает, знаете ли. Но мы сейчас не про языковые модели (с ними-то как раз всё понятно и вопросов вообще нет).
- Никакого "параллельно" там не было. Массив данных не рассматривался как база знаний. Только как база текстов. Никто не фильтровал информацию по принципу обосованности, подтвержденности или еще чего-то. Он рассматривался как база текстов. Если вы читаете по английски, то вот вам хорошая статья. writings.stephenwolfram.com
И вот честно говоря читая как вы тут рассуждаете на темы ИИ, теряется доверие ко всему тому, что вы писали и на другие темы. Если все настолько поверхностно, то думаю логично будет просто не тратить время на чтение ваших опусов.
И чтоб два раза не вставать, да я сама не слишком понимаюво всем этом, хотя и стараюсь разобраться хоть на любительском уровне. Но муж работает в этом направлении последние лет семь. И хоть на данный момент специализируется на ИИ в графике и видео, с языковыми моделями тоже работал. Поэтому не дает мне поверить в завиральные идеи усиленно распространяемые в прессе и прочих медиа.
Генерация осмысленных (!!!) текстов (со всеми фактами-датами-цифрами) по заданной тематике, да без базы знаний – это просто вау!!! 🙂
Ну, а если серьёзно, то "база текстов" (как вы её мило-непосредственно назвали)) – та самая база знаний и есть. Её ChatGPT анализирует, на ней и обучается (это если совсем вкратце). Всё просто.
На одной лишь "голой статистике" – полноценного смысла никак не выстроишь (дабы убедиться в этом, просто сравните частоту употребления различных слов в текстах, подавляющее большинство из них не будут иметь к запросу ни малейшего отношения, а будут лишь "связующими звеньями" в предложениях)).
То бишь, ChatGPT (как и любые прочие ИИ-системы) сначала "умно" выстраивает общие логические связи между ключевыми словами – а только уже после этого заполняет "пробелы" между ними остальным текстом, облекая выдачу в удобочитаемую для человека окончательную текстовую форму.
В любом ином случае, без анализа логических связей – в выдаче будет просто полнейшая и абсолютно бессвязная белиберда.
P.S. При этом, разумеется, вышесказанное вовсе не означает, что ChatGPT якобы "реально понимает смысл". Нет, разумеется. Но он максимально достоверно это имитирует (ну, хотя бы насколько может)))...
chat.openai.com
Ответил:
"Как я уже упоминал, я базируюсь на модели GPT-3.5 и имею доступ к огромному объему знаний, который был собран из множества источников, включая Интернет, книги, журналы, базы данных и другие ресурсы. Однако мой кэш знаний был обновлен в последний раз в сентябре 2021 года, и некоторая информация может быть устаревшей или неточной."
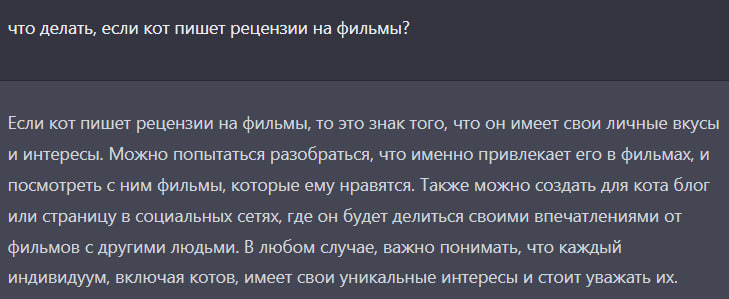
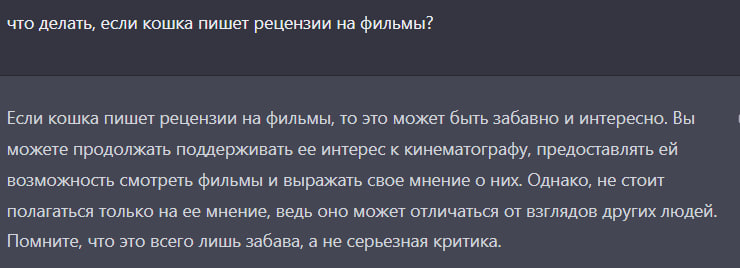
Кстати, с этим словом справится?
ChatGPT мне три раза считал, все три раза лажал в вычислениях, искренне извинялся, когда я ему указывал, на каком именно шаге он ошибся и снова лажал. В итоге я просто взял плотность металла из его вычислений, которую уже не надо было искать, и посчитал сам.
Когда надо было найти числа из колонки А. которые в сумме дают числа из колонки Б (примерно по 10-20 значений там и там) тоже не справился.
P.S. А в чём считали-то, если не секрет? ArchiCAD такое точно "могёт" "искаропки", AutoCAD тоже, ЕМНИП.
Спросишь например: "Как доехать от и до"
Ответит с Курского вокзала до "куда надо".
Но никогда не было и нет... (я проверил ;o)
______
© Народная мудрость



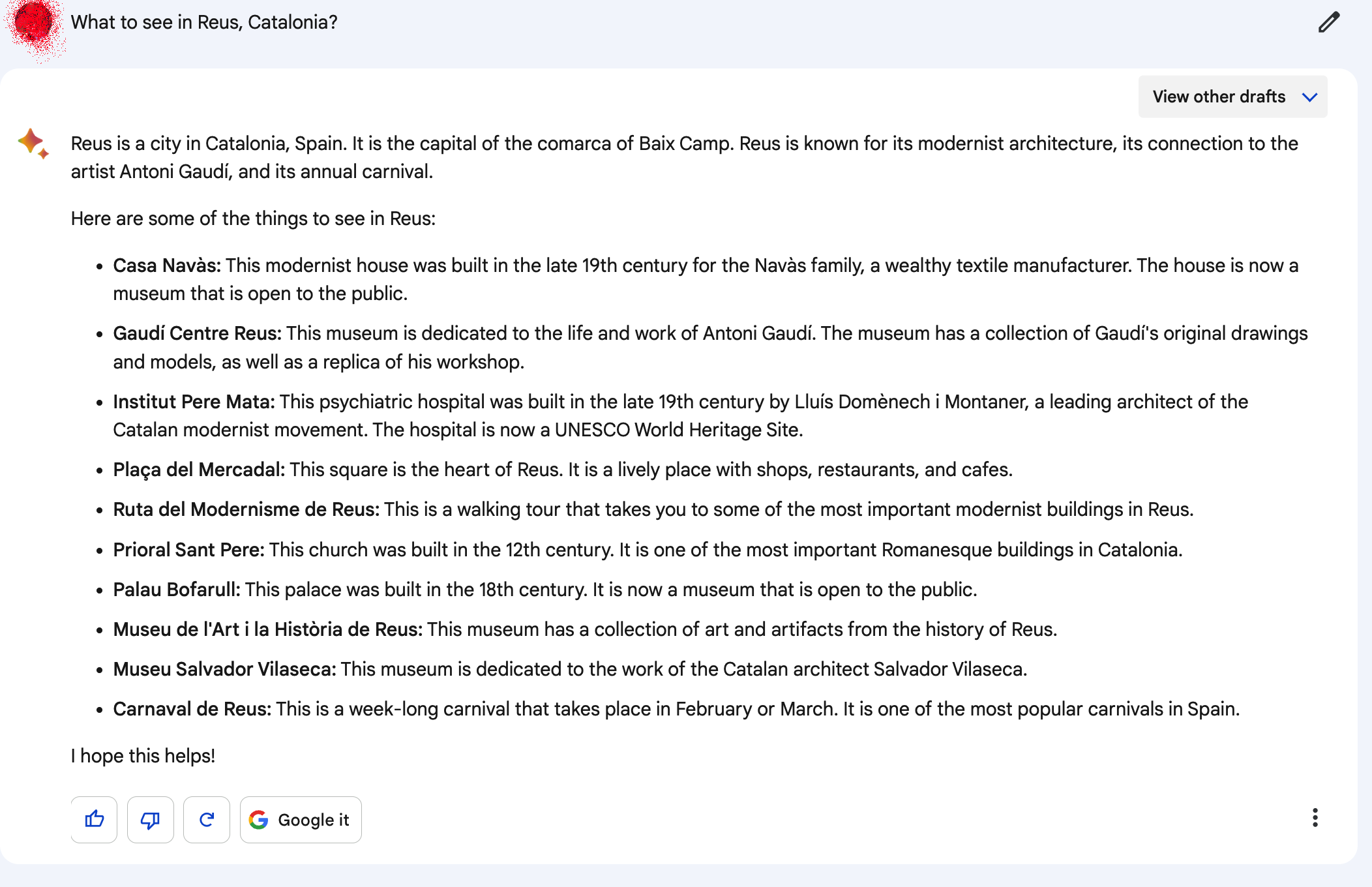
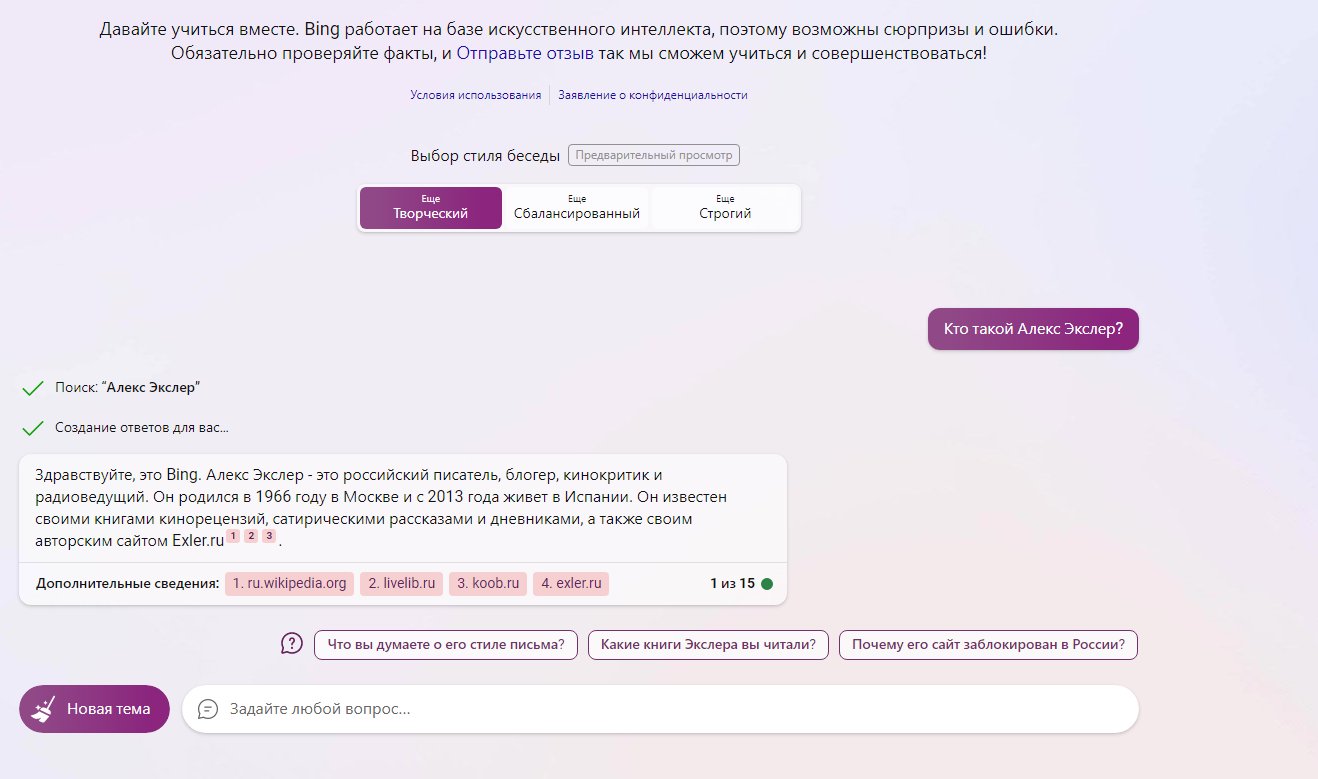
Реус является одним из главных городов провинции Таррагона, Каталония, Испания. Вот несколько интересных мест, которые стоит посетить в Реусе:
1.Площадь Прим (Plaça del Prim) - исторический центр города с множеством кафе и ресторанов.
2. Гауди-центр (Gaudí Centre) - музей, посвященный жизни и творчеству знаменитого каталонского архитектора Антонио Гауди. Гауди родился неподалеку от Реуса, в Реусе началась его карьера.
3. Музей искусств и истории Реуса (Museu d'Art i Història de Reus) - здесь вы найдете коллекции искусства и исторических артефактов, отражающих культурное наследие Реуса.
4. Площадь Меркадаль (Plaça Mercadal) - другая известная площадь города с зданием ратуши и живописными улицами вокруг.
5. Современный архитектурный ансамбль Института Перейра (Institut Pere Mata) - знаменитый пример модернистской архитектуры, созданный Ллуисом Доменечом и Монтанером.
6. Церковь святого Петра (Església de Sant Pere) - красивый католический храм, сочетающий в себе элементы готического и барочного стилей.
7. Бельведер Ла Сабинёса (Mirador de la Sabinosa) - с этой точки открывается великолепный вид на город и окружающую природу.
8. Парк города Реус (Parc de la Ciutat) - прекрасное место для прогулок, отдыха и занятий спортом на свежем воздухе.
Кроме того, Реус является отличной отправной точкой для посещения близлежащих достопримечательностей, таких как курортный город Салоу, тематический парк Порт Авентура, город Таррагона с его римскими археологическими памятниками и, конечно же, Барселона.оде Реус в Каталонии
А вот генерирует он отлично. Где-то лучше, где-то хуже, но в целом очень и очень неплохо.
Поэтому не стоит его найти информацию, его стоит просить что-то сделать - "вот у меня такие исходные данные, сгенерируй такое-то".
Другое дело, конечно, если пытаться сгенерировать что-то на научную тематику. Сгенерирует-то оно, может, и нормально, но какие именно факты будут взяты за исходные - это большой вопрос.
Да, в качестве базы знаний чаще всего используется поиск по интернету (ну а чего вы ещё ждали-то, если это и есть самая объёмная база в мире?))) – но "рерайтит" и компилирует найденные тексты эта штука чаще всего достаточно толково. То бишь, как минимум языковая модель там действительно вполне себе "ИИнтеллектуальная"...
P.S. Я вам больше скажу...
Если даже вдруг когда-нибудь и будет тот самый "полноценный ИИ" (что пока маловероятно, но допустим условно)) – то даже он будет вовсю использовать для обучения именно интернет. Никакой другой настолько же объёмной базы знаний просто не существует на свете.
Вот с этим у ИИ большие проблемы. То что он способен нахватать знаний из интернета - несомненно, но вот обрабатывать, экстраполировать, создавать абстрактные но при этом логичные концепции - этого пока даже в первом приближении не вижу. Пример деятельности интеллекта - победа при Гавгамелах или Аустерлице, которых по всем логикам быть не должно было, преодоление гравитации, открытие новых, неизвестных на момент обучения законов и принципов физики и прочих естественных наук. Как то так.
Вот, Вассерман - начитанный энциклопедист, на первый взгляд умный. Но спроси его не научные факты а попроси от себя высказаться - имбецил жеж, не иначе. Так и тут

Сам всегда говорю, что в обозримом будущем – просто невозможно искусственно создать даже какой там захудалый "интеллект", не то что уж аж сразу якобы "разум" (ибо пока сами понимаем в этом лишь немногим более, чем мартышка в ядерной физике))). Точнее, создать и громко назвать-то вполне себе могут – но будет это всё один хрен ненамного умнее бутылочной пробки. Как и сейчас. 🙂
В пошлых постах были ссылки на очень хорошее обьяснение как это все работает. Хоть бы кто-то почитал прежде чем высказывать свое "экспертное" мнение.
В целом же...
Никакой "прорыв в области ИИ" просто невозможен, пока мы ещё полностью не изучили механизмы действия своего собственного разума, не алгоритмизировали их хотя бы на первом приблизительном уровне. То есть, разработчикам нужна рабочая модель для подражания, если совсем грубо.
Пока этого не случится – любые ИИ так и будут пусть даже и сверхмощными, но по сути всего лишь не особо умными "большими калькуляторами". Это просто по определению.
Только с одним отличием - кораблик не получается
ЧатГПТ правда, на эту просьбу зачитал длинную ханжескую нотацию.
В Реусе есть много интересных мест для посещения! Один из самых популярных туристических объектов в Реусе - это Casa Navàs, здание в стиле модерн, построенное архитектором Луисом Доменеком и МонтанеромAd1. В доме можно увидеть множество оригинальных деталей и узнать больше о жизни и творчестве архитектора2. Еще одно интересное место - это Gaudi Centre Reus, музей, посвященный жизни и творчеству Антонио ГаудиAd1. Также можно посетить Institut Pere Mata - психиатрическую больницу, построенную в стиле модернAd1.
Я надеюсь, что это поможет! Дайте мне знать, если у вас есть какие-либо другие вопросы.
По заданью эФэСБе...
Для пресс-конференций.
Интересно спросить, чьи Крым и Херсон...
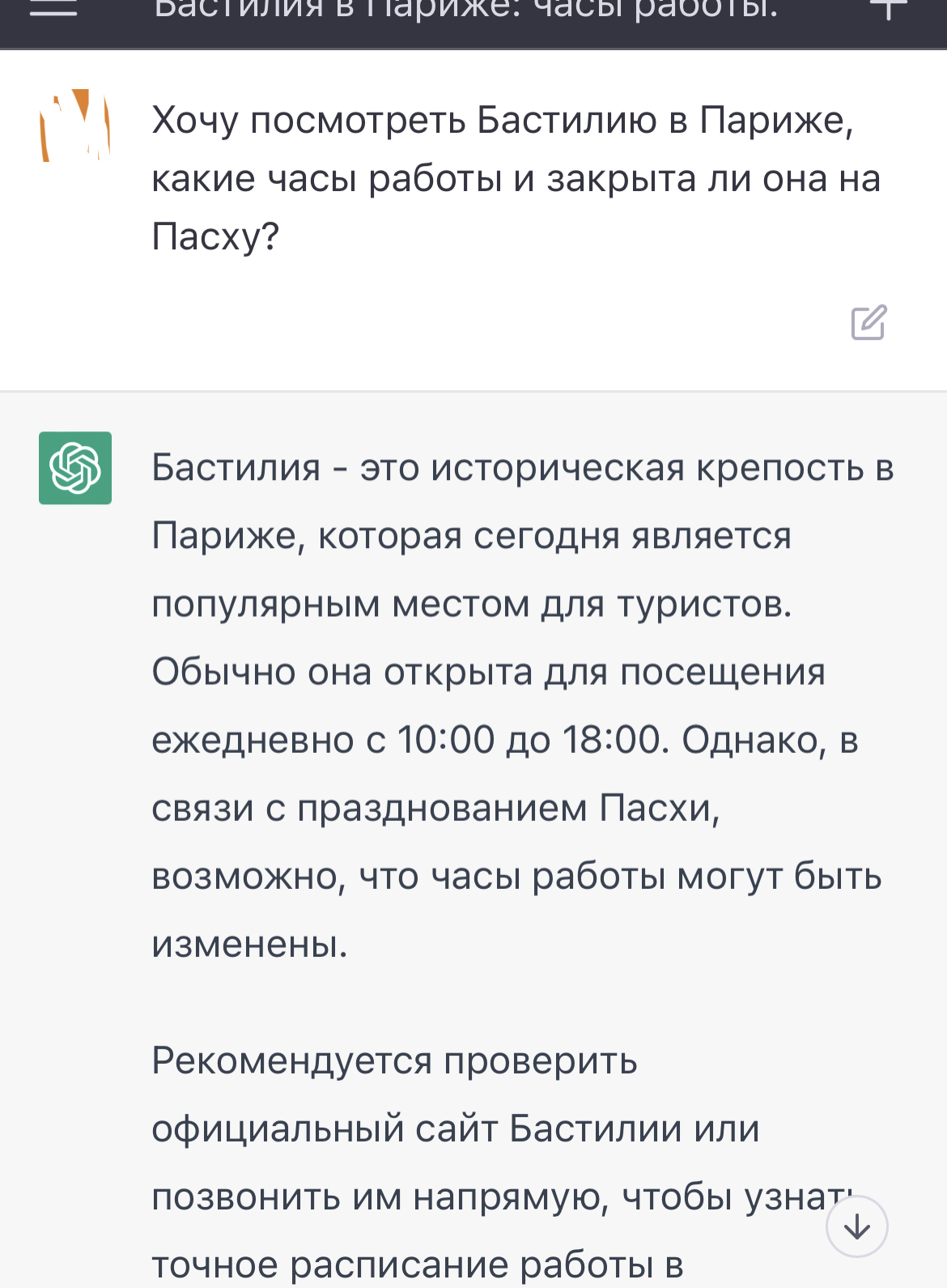
Давайте, сразу с козырей зайдём лучше, а то давно я что-то на парапет Бастилии в Париже не забирался.
Всем советую для посещения крепость - впечатляет! Только позвоните им сначала, чтобы узнать - вдруг на Пасху закрыты. Можете спросить у газетчиков в округе - они очень любят отвечать на вопрос о часах работы Бастилии.
Одни тапки остались.
Недавно протестировала его переводческие таланты (англ - ру). Небольшой отрывок из научпоп книги он перевел довольно точно, но одни термин придумал сам. Вот буквально взял с потолка, изобрел новое слово. На мой вопрос, что означает этот термин, он дал определение, которое точно подходит к термину в англоязычном оригинале, и, соответственно, к контексту переведенного отрывка. Если не знать, что термин придуманный, и использовать его, например, в статье или курсовой, то можно очень здорово лажануться.
Идея сюжета была разработана Джеймсом Кэмероном вместе со своим другом, писателем Уильямом Гибсоном, который уже пользовался популярностью среди поклонников научной фантастики благодаря своим книгам "Нейромант" и "Город героев".
Фильм начинается в 2085 году, где на Земле происходит глобальная эпидемия вируса, превратившая людей в плотоядных зомби. Очень вскоре вся планета была заражена, и человечество было вынуждено искать новый дом на Марсе. Спустя 258 лет карантина, пилот Кайл (Арнольд Шварценеггер) попадает в бурю космической пыли и его корабль терпит крушение на покинутую Землю в зоне джунглей, где когда-то располагался Манхеттен.
Кайл обнаруживает, что зомби на Земле не только выжили, но и адаптировались к новым условиям, став царями природы. Вскоре Кайл встречает женщину-инопланетянку, по имени Вета, роль которой сыграла Сигурни Уивер. Вместе они начинают искать выход из опасной ситуации и сталкиваются с воином-охотником из другого измерения, по имени Тарр, сыгранный Жан-Клодом Ван Даммом.
Тарр начинает охоту на Вету, так как она является опасной межгалактической террористкой. Кайл и Вета решают пробраться сквозь джунгли к заброшенным инопланетным звездолетам, чтобы покинуть планету. Но задача усложняется тем, что дорога проходит через племя зомби и загадочных мутантов - синих человекоподобных существ с телепатическими способностями, которые могут управлять армией мертвецов силой своей мысли... А по пятам наступает вооруженный до зубов охотник за головами.
Фильм был выпущен в 1985 году и стал мгновенным хитом. "Terragenesis" привлекал зрителей захватывающими сценами боя, высоким уровнем напряжения и уникальным миром будущего. Картина также выделялась захватывающим саундтреком, который был написан известным композитором Джоном Уильямсом.
от Midjourney и ChatGPT.
фильма нет, это не снятый фильм от нейросети

"Холодильник какого размера влезет в ВАЗ 2104?"
"Проходной габарит по высоте между Петербургом и Москвой"
"Где собирать грибы рядом с деревней Рахья"
ну и т.п.
И ничего вразумительного он не ответил, никакой филигранной работы ИИ не продемонстрировал. Абсолютно банальный набор ссылок, как и у Гугла. Так что пока революции не вижу.
"Проходной габарит по высоте между Петербургом и Москвой"
"Где собирать грибы рядом с деревней Рахья"
– Ага-а-а!!! – торжествующе сказали русские мужики и снова пошли валить лес двуручными пилами...
© Напомнило почему-то... 😁
"Проходной габарит по высоте между Петербургом и Москвой"
"Где собирать грибы рядом с деревней Рахья"
По второму - найти и сделать выжимку из документов. А если таких нет в открытом доступе, то можно по гуглопанормам дороги распознать дорожные знаки ограничения высот под путепроводами и тоже текстом мне написать, где самое низкое значение.
По грибам - подтянуть обсуждения с каких-нибудь форумов. Или хотя бы обвести рамкой на карте, где вокруг дервени лес (а не поле, или болото).
Но никакого ИИ в Бинге нет, это обычный поисковик, и нифига он не умеет.
Кафе "Рина".
-Но она же такая красивая!..
-Хорошо. Но потом - сжечь!
Чиорд, ща до оскорбления чувств верующих...
Зажимали в углу еще.
Святая Каферина,
Пофли мне дворянина.
Пофли мне дворянина.
Святая Катерина,
Мне лайкни дворянина!
В Тик-Токе уж хотя бы,
Я больше не прошу!
Вообще, забавно потому, что "ф" в кириллицу в своё время вводилась именно для того, чтобы "th" обозначать...
это тестовой генератор. Он в правдоподобной и убедительной форме выдает текст, который иногда только совпадает с реальностью. Его же легко можно убедить, что 2+2 будет 5.
Но в своих ответах "из области общих знаний" – ChatGPT таки чаще всего опирается как раз на результаты поиска (ибо "всё на свете" в его базы просто не встроишь, как ни старайся). И вот тут-то во весь рост вылезают его недочёты в данном аспекте – как видно даже на примере в посте Алекса.
То бишь, весьма неплохой такой "фидбэк" получился.
Если в ответ он будет выдавать какую-нибудь случайную белиберду (информацию про ДВС в ответ на запрос рецепта пирога, например))) – то и толку с него никакого. Следовательно, требуется и некая "база знаний", и выстроенные "тематические" цепочки связей.
Не знаю как версия 4, а 3.5 не была подключена к интернету.
Не знаю как версия 4, а 3.5 не была подключена к интернету.
А вот для ответов на всевозможные каверзные вопросы-запросы достопочтеннейшей публики – тут уж без интернета точно никак, одними лишь словарями ну никак не обойдёшься, такие объёмы информации ни в одну локальную БД просто не влезут...
Судя по ответам на юзерские вопросы – ChatGPT как раз-таки и пользует на всю катушку именно интернет. Иначе откуда бы ему ещё "нахвататься" всяких откровенных глупостей? Неужто их "специально вносили в базу" сами разработчики, "специально для дискредитации" своего же детища?! 😉
ChatGPT is not connected to the internet, and it can occasionally produce incorrect answers. It has limited knowledge of world and events after 2021 and may also occasionally produce harmful instructions or biased content.
Отсюда:
help.openai.com
Идея "
И даже все ограничения "не позже 2021" – практически уверен, что продиктованы банально последней датой индексации базового набора наиболее важных статей (которые действительно могут быть и в локальной БД, благо их не особо много)). В остальном – тупо поиск.
Просто потому, что чудес не бывает.
Больше данным взяться просто неоткуда, кроме как из того самого интернета. Поэтому новоявленный Deux ex machina – не более чем всё те же старые технологии и данные, только в новой и более умной "обёртке" (но на порядки более умной и продвинутой "обёртке", это вот признаю честно и абсолютно!).
P.S. Короче, я вовсе не "против" этой штуки, она реально классная! Но я категорически против её мифологизации (как это сейчас невольно происходит с вашей стороны)...
Я например проверял как он справляется с простенькими задачками по программированию - вместе с разумным кодом он домешивал классы, которые в данном языке программирования просто не существуют.
В целом же, про данные – см. выше. Просто невозможно запихать всё в одну локальную БД. Вообще. Никак.
Мне, например, тоже при поиске примеров на "ванильных" JS/CSS – то и дело "подсовываются" сайты с примерами кода на всяких там
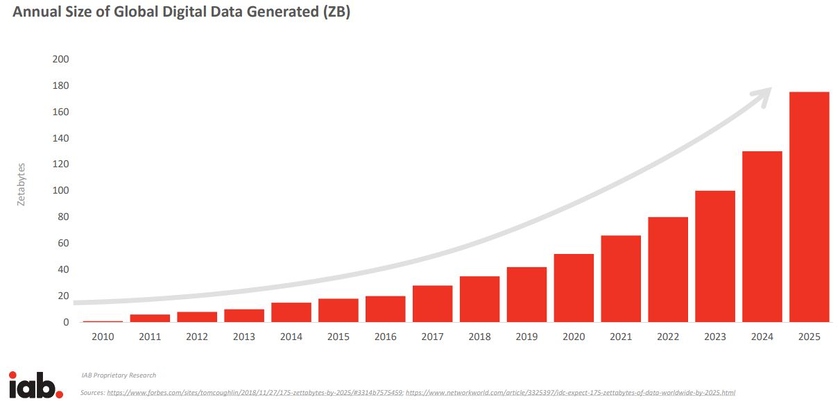
Объем базы текстов, на которых было проведено обучение 3.5 - 470 Гб. Это много для текста. Для справки, размер текстов Википедии на английском в 2021 году был 33 с лишним Гб, включая разметку. И я вот вообще не удивлен, что словарь у сетки ого-го.
P.S. Ну, и отдельно про "ажно 470 гигабайт". Вот вам примерные объёмы информации в интернете. Понятно, что сразу минус половина, а то и три четверти всякие видео и картинки, но, тем не менее – даже не терабайты, а зетабайты, Карл, сотни их!!! 😉
А если действительно интересно, то предлагаю подумать над тем, зачем OpenAI разрабатывает и продает как отдельную опцию коннектор их сетки к внешнему миру. И кто тогда это покупает, если это и так есть, из коробки.
Разве у меня было где-то хоть слово про "обман"? Я всего-то лишь утверждаю (и утверждаю аргументированно, в отличие от слепой веры некоторых), что этот самый ChatGPT – вовсе не настолько якобы "умная" штука, как его везде преподносят.
Разве у меня было где-то хоть слово про "обман"?
Цитируете старый анекдот (так и вы говорите). Надеюсь о том, о чем речь в анекдоте, не будем спорить?
По теме - предлагаю остаться при своих. Мне вас не убедить, вам меня. Дискуссия не имеет смысла.
These models were trained on vast amounts of data from the internet written by humans, including conversations, so the responses it provides may sound human-like. It is important to keep in mind that this is a direct result of the system's design (i.e. maximizing the similarity between outputs and the dataset the models were trained on) and that such outputs may be inaccurate, untruthful, and otherwise misleading at times.
Вот вам уже сами авторы сказали прямым текстом. Достаточно? Или всё ещё нет? "При своих остаться", панимашь...
Но в одном вы точно правы – дальнейшая дискуссия смысла не имеет. Тупо за неимением самого предмета дискуссии, собссно... 😁
Или по современному, скармливая пачки перфокарт в считыватель?
В общем, вы похоже, демагог.
Модель обучалась на "живых" постах и комментариях. Как я и писал. Что конкретно в этом моменте вам до сих пор не понятно?
Цитата:
Но в своих ответах "из области общих знаний" – ChatGPT таки чаще всего опирается как раз на результаты поиска (ибо "всё на свете" в его базы просто не встроишь, как ни старайся).
Вы сейчас пытаетесь соскочить с вашего же утверждения, что ChatGPT при ответах лезет в интернет и что-то там ищет. Приводите как подтверждение этого тот факт, что обучение проводилось на данных из интернета.
Путаете теплое и мягкое (или пытаетесь запутать?), одним словом.
Вы, в свое время, наверное учили буквы по азбуке. Но ни один серьезный человек на этой основе не станет утверждать, что вы ею пользуетесь, когда сейчас набираете тексты.
Так же и модель - обучена на данных из интернета, но работает уже без него.
Поспорить изволите-с? Милости прошу! 🙂
Эээммм.... Видите ли, любезный вы мой глу... пардон, наивный человечек... Как я и писал выше – "скачать весь интернет" невозможно просто физически, там любой ЦОД просто тупо лопнет от такого объёма данных. Следовательно – остаётся лишь исключительно "живое отслеживание".
Впрочем, у вас там какие-то свои собственные законы физики. Поэтому валяйте, "опровергайте" эту гнусную клевету... 😁
Скорее уж, это вы чрезмерно мстительно-злопамятный, судя по такому комментарию-то... Если в прошлый раз прищемил хвост слишком уж сильно – тады честно сорри, не хотел и не желал, и всё такое там... 🙂
Карл!
Я скорее поверю, что до 1/4 пользовательского интернета это только один ютуб. А в ютубе 99.9999%, это видео.
А оставшиеся 3/4 это все остальное. И из этого всего остального надо отнять Тик-ток, Нетфликс и прочие сервисы, завязанные на видео. На это уйдет, ну... допустим, процентов 80% (от 3/4 разумеется). Из оставшегося надо удалить сервисы с фотками. После этого, боюсь, что на осмысленную текстовую информацию и 1% не останется.
Карл!
Я скорее поверю, что до 1/4 пользовательского интернета это только один ютуб. А в ютубе 99.9999% это видео.
А оставшиеся 3/4 это все остальное. И из этого всего остального надо отнять Тик-ток, Нетфликс и прочие сервисы, завязанные на видео. На это уйдет, ну... допустим, процентов 80% (от 3/4 разумеется). Из оставшегося надо удалить сервисы с фотками. После этого, боюсь, что на осмысленную текстовую информацию и 1% не останется.
P.S.
Ну и потом, еще бы неплохо бы понимать, что входит в Digital Data Generaded. Вот, допустим, стоит станок, работает и херачит на сервер компании логи. Это Digital Data Generaded или нет? Или Алекс делает бэкап своего компьютера на амазон и его же копию в ОнеДрайв. Это считается в Digital Data Generaded?
А мильярды корпоративных электронных писем? А мильярды сообщений и котиков в Ватсапе и однокласнниках? А служебные СМС с одноразовыми кодами или рекламой?
А хцлиарды камер видеонаблюдения? Это все еще Digital Data Generaded или какая-то другая дэйта?
если все это входит в Digital Data Generaded, то при таком раскладе, ютуб конечно до 1/4 никак не дотянет. Но и на текст тогда останется тысячная или миллионная доля процента.
Может тогда и "ажно 470 гигабайт" - это не так уж и мало?
Даже на прямую ссылку со словами самих же авторов ChatGPT – тупо два тупейших минуса.
Вы, господа "правдорубы", определитесь уж – за реальную правду вы, или же исключительно за собственное личное
Зря доверяете (конкретно в данном вопросе), откровенно говоря.
ChatGPT is not connected to the internet, and it can occasionally produce incorrect answers. It has limited knowledge of world and events after 2021 and may also occasionally produce harmful instructions or biased content.
Это реальная правда или реальной правдой надо считать только ваши выводы, а авторы сами не знают как работает их ПО?
Так можно ли назвать это якобы "полностью автономной системой" (то бишь, "без интернета"), как вы считаете?
Или, всё же, первичный набор данных – сугубо из интернета и набран, и нет там никаких "специально созданных кастомных локальных баз", а есть лишь тупо распарсенные скачанные данные за 2021 год?
P.S. Хотя, конечно, этот момент вызывает большие вопросы. Зачем мудохаться с "тестовыми" локальными базами, почему бы не сделать/отладить сразу "живой" поиск по актуальным данным в сети – для меня загадка. Всё равно ж потом переделывать придётся, так нахрена "два раза бегать"?.. 🤔
Я вам написал, цитирую:
Авторы явно пишут,что это были данные из интернета.
Первая их модель, в частности, обучалась на выгруженном Реддите + все страницы по линкам с постов Реддита. Глубина, если я правильно помню, была вроде два уровня.
А вы во всех своих комментариях в этом посте утверждали, что ChatGPT просто хитро выполняет поиск и выдает обработанные результаты поиска.
Пример:
Данные из интернета – они и в Африке данные из интернета. Хоть в офлайн-режиме, хоть в режиме "живого" поиска – но это именно что данные из интернета, Карл!
Следовательно, ChatGPT "знает" только лишь то, что "знает" интернет (на момент последней даты парсинга веб-ресурсов и заполнения баз, соответственно).
Вы в терминологии-то определитесь для начала.
Давайте тогда ещё дальше пойдем - является ли "интернетом" база данных,
при условии, что она лежит у меня на диске и была наполнена данными из интернета (ну, например, небольшая БД в которую загрузили все статьи с сайта Экслера)? Как назвать поиск данных в такой базе - поиском в БД или поиском в интернете?
По вашей логике это и есть "поиск в интернете", а 99% айтишников скажут, что это обычный поиск в БД.
А если уж совсем передёргивать, то и данные в Интернете - они ведь появились как результат работы людей. Как статьи на этом сайте, не будем далеко ходить. Тут вообще один автор. Так может мы тогда даже не в БД и не в Интернете ищем, а в Алексе?
В попытках изворачиваться важно не доходить до абсурда.
А вот знаниями БД этого ИИ наполнена из интернета, так и есть. При первоначальном обучении. И никто и не утверждал обратного, ни я, ни другие комментаторы. Ну или процитируйте такое утверждение.
Кстати, ваша голова тоже наполнена была в школе умением читать и писать, но каждый раз при необходимости что-то написать вы в школу (как ИИ, по вашему, бежит в интернет) не идете и не просите учителя (видимо для ИИ это будет Гугл/Бинг) рассказать вам как и что написать. Пользуетесь, если попросту, своей БД в голове.
Проще говоря – важен источник информации, а не способ его хранения и/или доступа к нему.
Для пущего понимания сказанного – возьмите хоть тот же чёртов Ворд, например. Все его словари (БД) сугубо локальны, созданы и заполнены специально для него. Вот про него уже точно можно с полной уверенностью сказать, что он работает в полностью автономном режиме, и никакой интернет ему для обучения нафиг не нужен.
Ну хоть так-то понятнее, о чём речь? Или вы всё никак не можете абстрагироваться от буквального факта оффлайн-использования сетевых данных?
Подключили-скачали-отключили. Разве это считается "работает без интернета" (см. выше, пример с Вордом))???
Достаточно кратко?